Building a Semantic Search Engine with LlamaIndex : A Step-by-Step Guide
- Authors

- Name
- Abhishek Thakur
- @abhi_____thakur
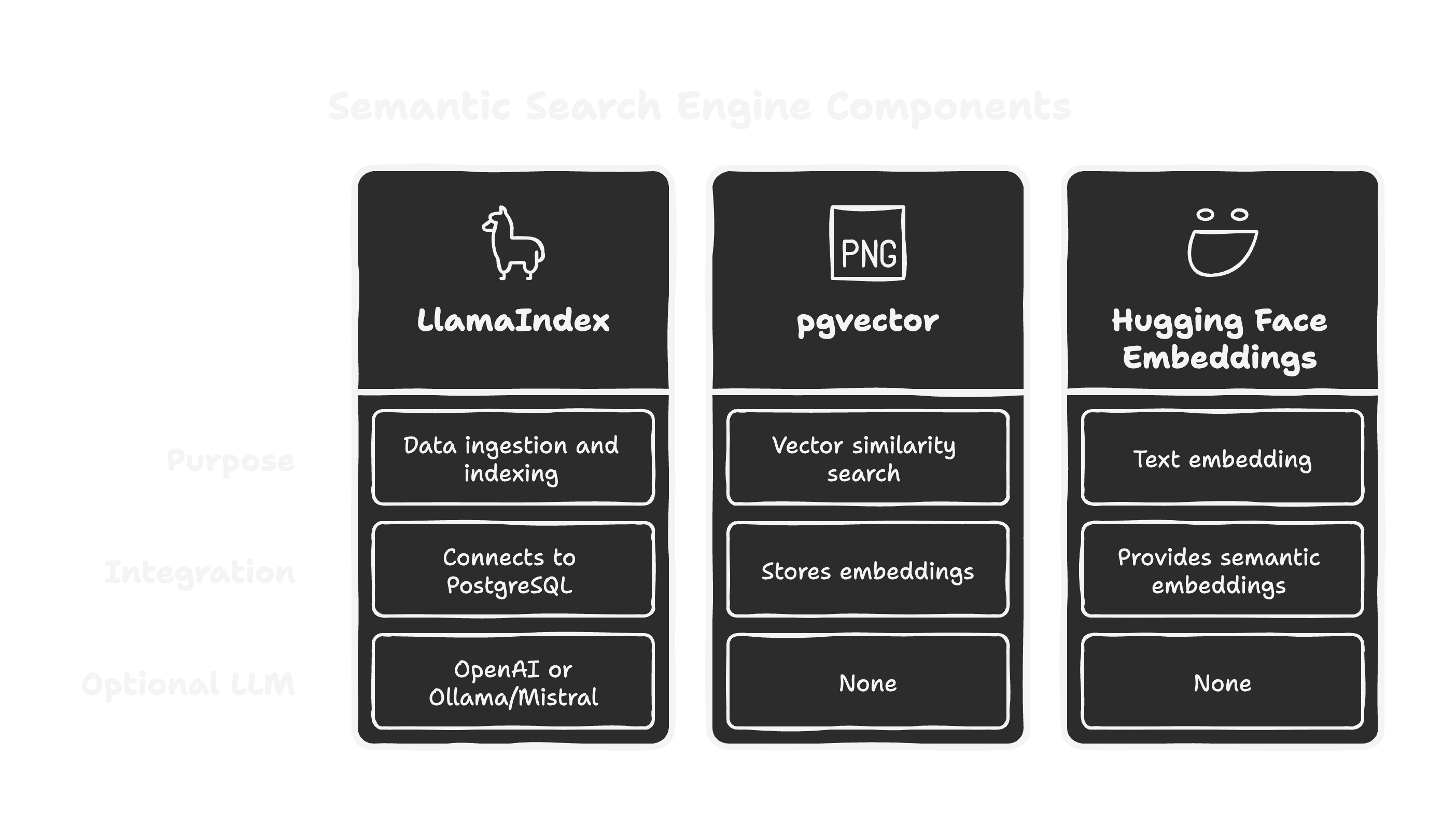
Semantic search enables understanding of meaning, not just keywords. In this guide, we'll walk through building a semantic search engine using LlamaIndex, PostgreSQL, and pgvector — powered by open-source LLMs and embeddings.
🧱 Overview
We'll use:
- LlamaIndex: To ingest and index data from PostgreSQL
- pgvector: PostgreSQL extension for vector similarity search
- Hugging Face Embeddings: For local, open-source text embedding
- Optional: Use OpenAI or Ollama/Mistral for generation
📦 Prerequisites
Python ≥ 3.8
A PostgreSQL database with your content
Install
pgvectorextension in your DB:CREATE EXTENSION IF NOT EXISTS vector;Install required Python packages:
pip install llama-index pip install llama-index-llms-ollama # or llama-index-llms-openai pip install llama-index-vector-stores-postgres pip install llama-index-embeddings-huggingface
🗃️ Step 1: Connect to Your PostgreSQL Database
Use LlamaIndex's SQLDatabaseReader to load data.
from llama_index.readers.database import SQLDatabaseReader
db_uri = "postgresql://user:password@localhost:5432/mydb"
reader = SQLDatabaseReader(uri=db_uri, include_tables=["articles"])
documents = reader.load_data()
🧠 Step 2: Generate Embeddings
We'll use Hugging Face's BAAI/bge-small-en for semantic embeddings.
from llama_index.embeddings import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en")
📥 Step 3: Store Embeddings in pgvector
Create a vector store pointing to your PostgreSQL DB.
from llama_index.vector_stores.postgres import PGVectorStore
vector_store = PGVectorStore(
connection_string=db_uri,
table_name="vector_index",
embed_dim=384, # Dimension of BGE-small embeddings
)
📚 Step 4: Build the Index
Now index the documents with your embedding model and vector store.
from llama_index import VectorStoreIndex, ServiceContext
service_context = ServiceContext.from_defaults(embed_model=embed_model)
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context,
vector_store=vector_store
)
🔍 Step 5: Query the Search Engine
Create a query engine and start searching.
query_engine = index.as_query_engine()
response = query_engine.query("What is semantic search?")
print(response)
🧪 Sample Output
Semantic search refers to searching for content based on meaning, not just keywords. For example...
🔁 Optional: Use an LLM for Generation
You can replace the default response generator with OpenAI, Ollama, or any custom LLM.
from llama_index.llms import Ollama
llm = Ollama(model="mistral")
service_context = ServiceContext.from_defaults(embed_model=embed_model, llm=llm)
🧰 Useful Tips
Run pgvector similarity queries manually:
SELECT content FROM vector_index ORDER BY embedding <-> '[embedding values]' LIMIT 5;You can chunk large fields before embedding using LlamaIndex’s
TextSplitter.
🚀 Conclusion
With just a few lines of code, you've built a powerful semantic search engine over PostgreSQL using LlamaIndex and pgvector. You can extend it by adding:
- Web UI (Streamlit, Next.js)
- RAG pipelines
- API endpoints (FastAPI)